True Love is Letting (Your Domain Model)
Go … Gently
Things change. And when you work in software development, things change fast. Eventually — and there is no escaping it — a fundamental assumption in your application’s design will prove to be outdated.
Sometimes, this core assumption will be so ubiquitous that it is found everywhere in your product, from the UI to the server to the database. This is especially true when using a framework like Rails, with all its assumptions about models and names. Everything about how your application works depends on this assumption being true. After all, why would this assumption ever not be true? But then, one day… it’s not. You are faced with the fact that a central, invincible part of your beloved domain model has reached the end of its lifespan.
There are infinite reasons why this might happen. In our case, the company wanted to launch a new product line that benefited from re-using most of the existing infrastructure. However, what used to be a simple one-to-one relationship between a customer and how they used the product needed to evolve into a many-to-one relationship involving multiple models and database tables. And our One Assumption, which permeated the entirety of our application, simply wasn’t true anymore.
The Endgame
The following diagram demonstrates our starting point, and where we ultimately needed to go.
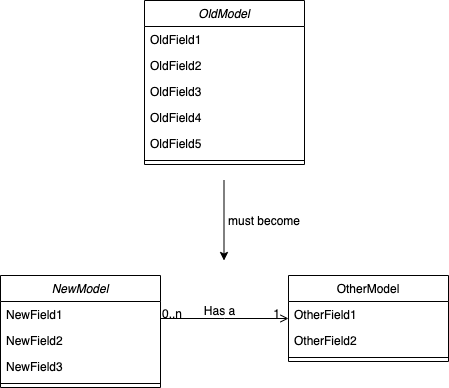
Sure, the cute diagrams make this seem like it should be easy enough. But consider that a single database table has become multiple database tables, and that this domain concept is used across multiple services. Also consider some of the fields have been renamed or moved, such that the code had to change in more complex ways than simply asking the IDE to Refactor→Rename:
# What used to be... old_model.old_field_1 # ...might change names new_model.new_field_2 # ...or even need to access another object new_model.other_model.other_field_1
We knew it would be impossible to do this in one deployment. There was too much code to change, too many services affected and too much risk involved. We also knew that we needed this to be a zero downtime operation; the code we were touching was so critical that we would have lost new user installs, affected day-to-day operations and been in very deep trouble if anything at all went wrong during deployment. No one needs that kind of stress in their life.
The Execution
We designed our game plan so that this work could be done over any number of deployments, over any duration. We needed to be able to stop the work halfway through — if something more pressing came up, for example — while also ensuring that we didn’t introduce any “gaps” in data which would require us to go back and apply manual fixes. The first deployment was critical to get the ball rolling, but the rest of the work could be done in any order, at any time and with little risk.
Deployment 1
The purpose of the initial deployment is twofold:
- Redirect the old model to the new tables. With the exception of the model we are actively deprecating, our goal is to leave the entirety of the codebase untouched. Any references to the old model and methods still work exactly as they used to, they just secretly interact with a new database structure.
- Migrate the data. After this deployment, the old database table is no longer used in any way.
This first deployment contains more risk than subsequent ones, so we made sure to be extra careful about testing exhaustively and discussing any potential issues early on. We used a combination of existing unit tests, new unit tests, manual testing, as well as GUI automation tests.
Redirect the Old Model
This step ensures that the existing model, OldModel, can still be used safely in any code that we haven’t had the chance to refactor yet. In order to do so, we need to heavily modify the class so that it exposes the exact same API as it used to, while in reality utilizing the new database structure.
First, we need to make the old model communicate with the new database table. This one is easy:
class OldModel < ApplicationRecord self.table_name = 'new_models' end
Next, we deal with any attributes that have been renamed using alias, allowing us to continue using them as if nothing had changed:
class OldModel < ApplicationRecord ... alias old_field_1 new_field_1 alias old_field_1= new_field_1= end
Finally, we need to account for the new association to OtherModel that was added. We need calls to OldModel.old_field_3 to act exactly the same as NewModel.other_model.other_field_1. For this, we use a combination of alias and delegate:
class OldModel < ApplicationRecord ... alias old_field_3 other_field_1 alias old_field_3= other_field_1= delegate :other_field_1, :other_field_1=, to: :other_model, allow_nil: true end
Migrate Existing Data
As shown in the diagram above, we converted a single database table into two tables, and spread the columns between the two. The concept was simple enough: Iterate over all the rows in the old table and create entries in the new tables based on the existing data, ensuring the new association exists. We also wanted to make sure the IDs in the new tables matched the old IDs, because we have some external tools and reports that rely on that ID. Here’s a naive first attempt:
OldModel.find_in_batches do |batch|
batch.each do |old_model|
other_model = OtherModel.create!(
id: old_model.id,
other_field_1: old_model.old_field_3,
)
NewModel.create!(
id: old_model.id,
new_field_1: old_model.old_field_1,
new_field_2: old_model.old_field_2,
other_model: other_model
)
end
Unfortunately, there are a number of problems with this approach. First, OldModel.find_in_batches no longer loads data from the OldModels table (because we told it not to in the step above!). To solve this, we created a dummy model whose sole job was to load OldModel instances from the correct table.
class LegacyOldModel < ApplicationRecord self.table_name = 'old_models' end
The second issue is that by filling in the IDs manually, the sequence numbers in the tables are not updated accordingly, which would result in duplicate primary key errors down the road. This can be fixed by using setval at the end of the script:
connection.execute("select setval('new_models_id_seq', (select max(id) from new_models))")
Third, this migration script is slow. When we ran it against a clone of our production database, we found that it would take roughly 6 hours to complete, which is contrary to our requirement of having no downtime. Using pure ActiveRecord to run a migration of this size is a bad idea. There are far too many objects being instantiated, validations being run, callbacks being invoked — not to mention that every call to the database results in only a single row being created. In order to speed things up, we bypassed ActiveRecord completely on the insert side of things, did some reverse-engineering on how Rails creates SQL INSERT statements based on model data, and went lower-level.
Our final migration script looked like this:
def up
# Our “loader” model, LegacyOldModel
LegacyOldModel.find_in_batches do |batch|
other_model_insert_statements = []
new_model_insert_statements = []
batch.each do |old_model|
other_model = {
'id' => old_model.id,
'other_field_1' => old_model.old_field_1,
)
new_model = {
'id' => old_model.id,
'new_field_1' => old_model.old_field_2,
'new_field_1' => old_model.old_field_3,
'other_model_id’ => other_model['id']
)
other_model_insert_statements.append to_sql_insert(OtherModel, other_model)
new_model_insert_statements.append to_sql_insert(NewModel, new_model)
end
# Execute all INSERT statements in this batch at the same time
connection.execute((other_model_insert_statements + new_model_insert_statements).join(';'))
end
# Because we manually inserted the IDs, we need to manually update the sequences
connection.execute("select setval('other_models_id_seq', (select max(id) from other_models))")
connection.execute("select setval('new_models_id_seq', (select max(id) from new_models))")
end
# Reverse-engineered how Rails creates INSERT statements based on model attributes
# We recommend looking at Rails 6’s insert_all method in the future.
def to_sql_insert(klass, attributes)
insert_manager = klass.arel_table.compile_insert(klass.send(:_substitute_values, attributes))
sql, _binds = connection.send :to_sql_and_binds, insert_manager, []
sql
end
This migration is more complicated, but it allowed us to get the execution time down from 6 hours to roughly 4 minutes. Not quite “zero downtime”, but close enough for us.
Sidenote: Rails 6 has introduced insert_all, which we did not have access to when we did this work. We can’t say what the performance would have been, but it definitely seems like this would have been a useful tool at the time.
Deployment 2
Our first deployment ensured we were using the new database structure without modifying any of the application code. This second deployment is the first step towards refactoring the codebase. In our case, we needed to rename any foreign keys called old_model_id to become new_model_id. This would ensure that, once our “dummy” OldModel was deleted, Rails could continue working normally.
We opted to clone the column, rather than renaming it, for safety. Creating the new column and populating it with the correct values is easy (without forgetting to create any indexes that the original column may have had!), but we also needed to make sure that we could write to both columns interchangeably, and that they would stay in sync. Otherwise we would get into a case where we had refactored half of the app to use the new column, but the other half of the app was writing to the old column, resulting in major headaches. We found it was easy to leverage the before_save callback in Rails to accomplish this:
before_save :sync_old_model_id_and_new_model_id
def sync_old_model_id_and_new_model_id
if old_model_id_changed?
self.new_model_id = self.old_model_id
elsif new_model_id_changed?
self.old_model_id = self.new_model_id
end
end
Deployments 3 and Beyond
This is where the hard work pays off. All the tools and guardrails are in place to refactor your entire codebase at your own pace and across any number of deployments you want. You can slowly swap out all references to OldModel for NewModel, updating any method names if they have changed. If your unit tests worked with OldModel, they should continue to work with NewModel, allowing you to refactor them at the same time.
Once you are satisfied that your entire codebase has been refactored, you can move onto the fun part: Delete the OldModel class and drop the old database table. (You may want to create an archive of it, just in case…)
The End
Changing the central pillar in a codebase is a little like changing a structural column on your front porch: you put in a jack to ensure your roof doesn’t collapse, then you do the swap. It can be daunting, but with a little planning and an effort to ensure the work is done in small steps, it can be done safely.
There will be pitfalls — bits of code you’ve forgotten about or realize had little or no test coverage — but, slowly, methodically, you will accomplish a difficult task without breaking too much of a sweat. And without setting fire to production.
We’re hiring. Come work with us!
We’re always looking for passionate and talented engineers to join our growing team.
View open career opportunities Marc Morinville">
Marc Morinville">