At Rewind, we’re big believers in the concept of “Infrastructure as Code” and we use a few tools to help us accomplish this. Being a big AWS user, I was very familiar with CloudFormation and joining Rewind, I started to use Terraform as well. I’m often asked the difference between these tools, why one over the other, how are they different, etc. so in this post, I’ll cover off what was the key difference for me and where each is applicable. I’ll also cover a little of how the Rewind infrastructure is set up and why having our infrastructure defined as code is so important.
What is Infrastructure as Code?
For me, Infrastructure as Code means a programmatic way to define your actual infrastructure so that it can be templated and re-used. This gives us a few benefits:
Speed: If your infrastructure is templated, you can use it to create entirely new environments very quickly. Recently, I turned up an environment for a brand new platform we are working on backing up in around an hour. This would have taken a couple of days before.
Security: We’re guaranteed that the right access controls will be applied across everything that is created. Everything policy driven has the same policy applied.
Reproducible: We know that we’re going to get the same configuration, environment, instance sizes across everything created from our templates.
I was at a conference last year where a presenter put up a slide saying that if you’re using the console, you’re doing cloud wrong. I don’t entirely agree with this – the console is great for experimenting – but for any serious setup beyond a couple of instances, having something well defined is a must.
‘As code’ means a programming language right? Not necessarily. AWS’s Cloud Formation uses either json or YAML. Terraform uses something called HCL. Azure’s resource manager uses json. I consider all of these infrastructures as code even though they could be viewed as just big configuration files. Really, the big thing is you can describe your infrastructure and it’s dependances in an orderly way and (critically), you can use the same version control system as your application code uses. In fact, the code for the infrastructure should live right alongside the application code. There’s really not much separating the application from the infrastructure it’s running on today.
The other big advantage to having your infrastructure defined as code is it can form a parameterized, reusable template for similar infrastructure. I’ll cover this a little more when I talk about how Rewind uses the concept of a pod to separate the various platforms we backup. By having a common template with parameters, we’re guaranteed that everything we need to look the same and follow certain standards will always just be there. For example, we use encryption everywhere. I’m guaranteed that I won’t have a rogue database without encryption enabled anywhere because the template is the same. Likewise, I won’t have an S3 bucket with a different lifecycle configuration because everything is based on the same template.

Pods
Who doesn’t love a good pod race? At Rewind, we backup multiple SAAS platforms with the list growing every week it seems. One of the (brilliant) decisions made prior to my joining the organization was to separate out the infrastructure into two distinct concerns:
- Edge – this contains components that are either common to multiple platforms or components that do not actually process data
- Pod(s) – the pods are where the magic happens. These are self-contained… well…pods that contain the workhorses for dealing with a platform. And each platform can have one or more pods depending on scaling or geographic requirements for data storage.
At a high level, the relationship between the Edge and Pods looks something like:
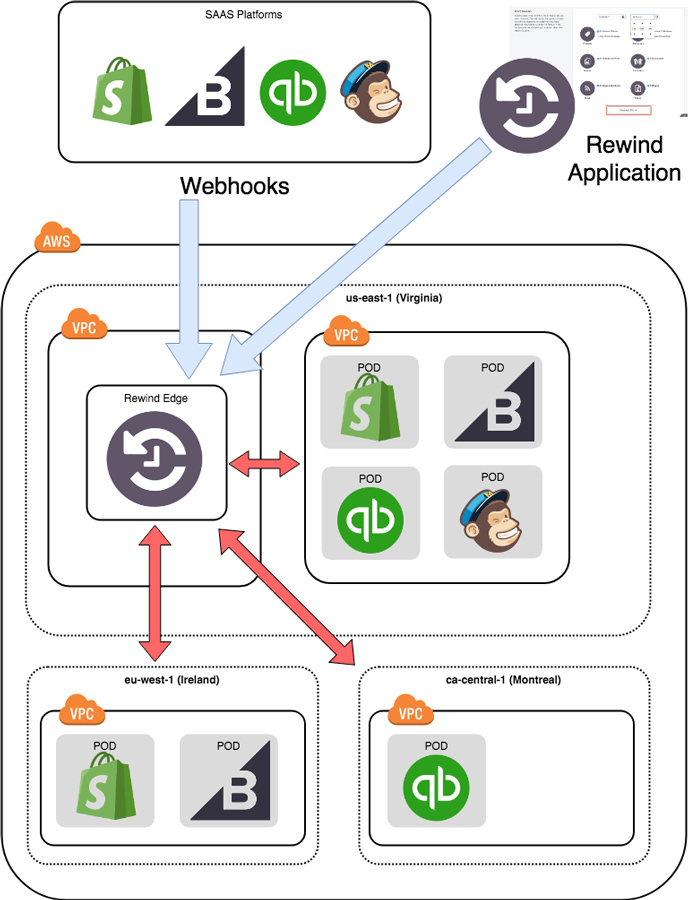
Each pod essentially consists of the same core components:
- Several AWS Elastic Beanstalk environments
- Some S3 buckets
- Some SQS queues
- An RDS database
- A redis cache
- An Elastic Search cluster
- Some cloudwatch alarms
- Some EFS shared storage
There’s some variance in the size of instances used, database size, etc. but generally each pod contains these core components. We run at least one pod for each platform depending on scaling requirements and data residency requirements. Users within a platform are assigned to a pod which also helps to reduce the scope if any issues occur with a single pod.
Generally, the platform backups are controlled within the pod itself but for webhooks which are triggered when an item changes, they are ingested by a centralized routing mechanism in the edge and directed to the appropriate pod for processing.
The pod model is perfect for being modeled in some infrastructure management tooling.
Terraform
For most of our infrastructure setup at Rewind, we’re using Terraform from HashiCorp. It’s very similar to AWS Cloudformation in what it can do but it has a few differences and one key feature which has been invaluable to us at Rewind. I won’t cover the basics of Terraform here (the Terraform tutorial is very good) but instead, I’ll highlight some of the features that have been useful to us in the context of creating pods.
Workspaces
Terraform has the concept of workspaces which allows you to separate the state for different areas of concern. We use S3 backing for our state and workspaces and have separate workspaces for each pod and our edge environment. We then use tfvars files for each pod/workspace with a naming scheme that makes it easy to match properties to a workspace. A simple shell alias allows us to make sure we’re applying the right variables to the right workspace.
Counts
One feature that Terraform has which Cloudformation does not is item counts where multiple items can be provisioned based on a count or the count can function as a boolean. In the case of our pods, we have some Elastic Beanstalk environments that are very similar with only a difference in configuration so we provision these with a count and then reference the config from a map. This snippet shows part of the Beanstalk creation using the count and also how we reference into a map containing a list of Sidekiq queues to use depending on the ID (count) of the environment:
resource "aws_elastic_beanstalk_environment" "cb_pod_workers" {
count = "${var.eb_sidekiq_worker_count}"
application = "${aws_elastic_beanstalk_application.pod.name}"
name = "${local.pod_name}-workers-00${count.index+1}" # Counts are zero indexed, we want to name starting at 1
description = "${local.eb_workers_description}"
solution_stack_name = "${data.aws_elastic_beanstalk_solution_stack.eb_solution_stack_ruby_puma.name}"
wait_for_ready_timeout = "40m"
tier = "WebServer"
setting {
namespace = "aws:elasticbeanstalk:application:environment"
name = "SIDEKIQ_PRIORITY_QUEUES"
value = "${lookup(local.eb_sidekiq_worker_queues[count.index], var.pod_platform)}"
}
}
This (edited) map is how the queue names are looked up depending on the worker ID (count):
eb_sidekiq_worker_queues = "${list(
map("bc", "queue1",
"sh", "quque1",
"qb", "queue1",
"mc", "default",
),
map("bc", "queue2,queue3",
"sh", "queue2,queue9,queue10",
"qb", "default",
"mc", "default",
),
map("bc", "default",
"sh", "export,default",
"qb", "default",
"mc", "default",
),
)}"
Without the use of count, we would have had to duplicate the Beanstalk environment definitions. Here we can be assured that with the exception of the queue variable, all the other configuration is exactly the same.
Remote State
Remote State is a feature of Terraform where the state from one workspace can be examined by another. In our example, we have a separate workspace/state that sets up the VPC for a region. This is rarely edited and it would be a very bad day is this was deleted by mistake whereas pods are edited fairly regularly. However, the pods need to know information from the VPC such as which subnets are available, access to the route table for VPC peering, etc. Using Remote State allows the pod workspace to get these values from the VPC workspace. For example, assuming our pods need info from the VPC, we can do this to reference the VPC remote state:
data "terraform_remote_state" "pod_vpc" {
backend = "s3"
workspace = "${local.pod_vpc_workspace}"
# these vars all come from the backend.tfvars file....
config {
bucket = "${var.bucket}"
key = "${var.key}"
workspace_key_prefix = "${var.workspace_key_prefix}"
region = "${var.region}"
profile = "${var.profile}"
}
}
In the example above, the only real interesting part is the workspace which we pass in from tfvars files. Everything in the config is just the standard back end configuration that tells Terraform where the state exists in S3. When using Remote State, the “client” can access anything that is defined as an output in the state. So for example, in our case we export the VPC ID and the subnets and access it like:
Pod_vpc_id = "${data.terraform_remote_state.pod_vpc.vpc_id}"
Subnet_a = "${data.terraform_remote_state.pod_vpc.public_subnet_a_id}"
Imports
This is the single biggest feature that really differentiates Terraform for me. While working on greenfield projects is great, it’s rare that you’re not inheriting something already existing. In my case, some of our infrastructure was in Terraform but a good amount was not. It was not practical to delete and recreate all of this production infrastructure and the downtime that would have ensued. Enter imports. Imports allow you to create the Terraform templates as normal and then import existing infrastructure into the state.
The hard part about importing is making sure your templates match the infrastructure properties you are trying to import. Seemingly small changes can mean that after importing the resource, Terraform will need to destroy it and recreate it to set a property which would be bad with production. For example, encryption cannot be enabled on a pre-existing RDS database so Terraform would need to replace it.
It was quite a long, fiddly project to import all our infrastructure but now we have everything under Terraform management, making changes is a snap.
AWS CloudFormation
With all of our edge and pod infrastructure under Terraform control, is there a place still for CloudFormation? The answer is yes – for specific use cases. The best example of which is a service (or services) which run in a container using the EC2 container service (ECS). Each service has a task definition, a service definition, some configuration and an optional load balancer and DNS entry. This is all perfect to package up in a CloudFormation template and deploy each service as a separate stack. Another example is services or applications created using AWS SAM (serverless application model) where SAM is using CloudFormation as the deployment mechanism.
Wrapping it all up
Whatever the toolset you’re using, treating infrastructure in the same way as code (version control, peer reviews) is something that should be done from day 1. Tools like Terraform let you import existing infrastructure so you don’t even have to start with a new project. A little investment pays off very quickly when you need to make changes or, as with our pod model, spin up very similar environments. With cloud computing, the line that used to separate the application from the infrastructure it runs on is essentially non-existent.
For more information about Rewind, visit rewind.com. Or, learn more about how to backup Shopify, backup BigCommerce, or backup QuickBooks Online.
We’re hiring. Come work with us!
We’re always looking for passionate and talented engineers to join our growing team.
View open career opportunities Dave North">
Dave North">